CIEID – Concise isiZulu-English Internet Dictionary
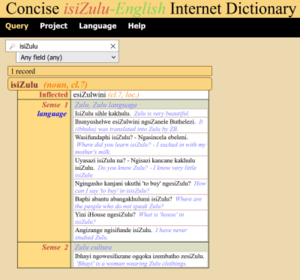
Das Concise isiZulu-English Internet Dictionary ist ein zweisprachiges Wörterbuch, das aus einem intensiven Sprachkurs am Institut für Afrikawissenschaften der Universität Wien hervorgegangen ist. Dieses Unterfangen wurde von der Erstellung eines umfangreichen Satzes an digitalen Lernmaterialien (Curriculum, Grammatik, Übungen, Texte, Wörterbuch) begleitet, die alle auf der Grundlage von TEI (P5) erstellt wurden.
Das Wörterbuch hat einen experimentellen Charakter, da es das erste am ACDH-CH war, das in TEI Lex-0 modelliert wurde. Es diente auch als Testumgebung für die Entwicklung des neuen lexikografischen Editors, des ˂TEI˃Enricher, und für Experimente zur halbautomatischen Datenerfassung/-erstellung für digitale Wörterbücher.
Der Schwerpunkt bei der Zusammenstellung des Wörterbuchs lag auf dem modernen urbanen isiZulu, einer Sprache, die zum Nguni-Zweig der südlichen Niger-Kongo-Sprachen im südlichen Afrika gehört. Das Volk der amaZulu (etwa 12 Millionen L1-Sprecher) lebt hauptsächlich in der Provinz KwaZulu-Natal der Republik Südafrika. Mit etwa einem Viertel der Bevölkerung Südafrikas ist IsiZulu die am weitesten verbreitete Sprache des Landes. Es ist eine der 11 Amtssprachen Südafrikas.
Die lexikografische Datenerfassung erfolgt auf zwei Wegen. Das Hauptziel besteht darin, alle lexikalischen Einheiten zu erfassen, die für das Lehren und Lernen von IsiZulu benötigt werden, Dies schließt lexikalische Einheiten mit hoher Häufigkeit, die in Lehrbüchern verwendet werden und typischerweise für den Unterricht der Sprache benötigt werden ein. Darüber hinaus lag der Schwerpunkt auf der Sammlung von Daten, die in anderen Wörterbüchern nicht zu finden sind. Besonderes Augenmerk wurde hierbei auf Neologismen und Lehnwörter gelegt, wobei vorläufig keine Vollständigkeit angestrebt wird.
Für die Zusammenstellung des Wörterbuchs wurde ein Korpus digitaler isiZulu-Texte verwendet, das aus verschiedenen Internetquellen, insbesondere Online-Zeitungen, zusammengestellt wurde. Einige wenige zeitgenössische literarische Werke wurden ebenfalls integriert. Die in TEI (P5) kodierten Daten wurden über NoSke durchsuchbar und für die lexikographische Arbeit verfügbar gemacht. Mit Stand vom 3.6.2024 enthielt das veröffentlichte Wörterbuch 15.417 Lemmata (Einzel- und Mehrworteinheiten) und 13.280 Beispielsätze.