May 8, 2024 | Eirini Afentoulidou, Cinzia Grifoni, Anna Michalcová, Jan Odstrčilík, Leon Pürstinger, Bill Weis | HI Research Blog
After last year’s success, we decided to organize the second year of HTR Winter School in Vienna. Because of organisational constraints, we planned for it to be smaller than before, while still preserving its quality and uniqueness: Participants do not only learn about using AI for reading medieval manuscripts in theory, but moreover they work in groups on specific manuscripts, transcribe them and then train their own AI models based on these datasets. Finally, the results are being published. You can read about this from our blog post last year Discovering the Power of AI for Reading Medieval Manuscripts: HTR Winter School 2022.
In the end, this winter school was practically the same size as the year before: Nine organizers, 44 participants, two virtual meetings and two days of in-person workshop in Vienna. The Winter school was organized again by the Institute for Medieval Research of the Austrian Academy of Sciences, this time with instructors from across central Europe: from the University of Vienna, Czech Academy of Sciences, Charles University in Prague, and Comenius University Bratislava.
We are also very grateful for the recurring support for the Winter School, not only by the Institute for Medieval Research itself but also from READ-COOP (developers of Transkribus), which gave us with free credits.
This year, we created four teams:
• Carolingian minuscule team led by Cinzia Grifoni, Leon Pürstinger and William Weis
• Late Latin team led by Jan Odstrčilík, Ivana Lukáč Labancová and Martin Roček
• Byzantine Greek group led by Eirini Afentoulidou and Ekaterini Mitsiou
• Last but not least, Anna Michalcová led the Czech team.
Carolingian Latin Group
The Carolingian group included ten participants at different stages of their academic career, who shared an interest in discovering how Transkribus can facilitate their engagement with Latin texts from the early Middle Ages. This team was led by Cinzia Grifoni, Leon Pürstinger, and William Weis, researchers associated with IMAFO. We chose to experiment with two manuscripts held at the Austrian National Library, the first (Cod. 473) containing the Liber Pontificalis, the second (Cod. 1239) transmitting a heavily annotated copy of the Pauline and Catholic Letters.
Our first virtual session was devoted to the text of the Liber Pontificalis as it is preserved in the 9th century codex ÖNB 473. This manuscript was chosen for several reasons. Most importantly, it was a relatively straightforward manuscript and the section we chose was in an uncomplicated and consistent scribal hand without many glosses: this would provide a clear and easy starting point for our model and for the participants to begin to learn to use Transkribus. Secondly, this manuscript was also used in the previous HTR Winter School 2022, which formed the basis for Tim Geelhaar’s model "Carolingian Minuscule Model CMM 9th-11th c.", which has a commendable character error rate (CER) of 5.2%. Ultimately, by the end of the HTR Winter School 2023, we hoped to compare our model with Prof. Geelhaar's, even though our data set was much smaller, hoping for a similar CER. First, we had participants manually transcribe roughly the first half of the text: we then used this data to train our own model and, after a first passthrough where participants corrected the model in order to improve its accuracy, we attempted to automatically transcribe more sections of the Liber Pontificalis. The results were promising, so we next attempted to use this same model on a more complicated document, ÖNB 1239.
In the second virtual meeting we started working with the manuscript Vienna, ÖNB 1239, a ninth-century commented edition of the Pauline and Catholic Letters conveying the biblical text in the central column of the page and a substantial apparatus of annotations in two marginal columns. Numerous glosses occur also between the lines. This was a pioneering endeavour and a new frontier in the use of Transkribus for glossed manuscripts. ÖNB 1239 has not been digitized yet, but we had access to pictures of roughly 40 pages at hand, which were unfortunately not in the highest possible resolution. It was therefore no surprise that we had to face several issues, regarding both the layout and the text recognition. It proved useful, for instance, to correct the automatic layout recognition and to create a region for each marginal annotation. As for the automatic text recognition, we used the model we had trained after our first meeting. This turned out to be very good regarding the biblical text in the central column, but it was inadequate for transcribing the marginal glosses, probably due to the resolution of the pictures and the small size of the script. Thus, we decided to manually correct the automatic transcription and to train the model again with our new ground truth. This last stage of work was conducted during our meeting in person. On this occasion, we also enjoyed the opportunity to admire and browse through the MSS 473 and 1239 at the National Library in Vienna.
We managed to generate impressive results for ÖNB 473 and the main column of ÖNB 1239, but still struggled with the marginal glosses. Therefore, we decided to train two individual models at our in-person meeting. Our first model was trained with the main texts of the two manuscripts without any glosses (using Tim Geelhaar's Carolingian Minuscule model as basis). We were able to achieve an excellent CER of 5.1%, and thus improve on Geelhaar's model! Our second model is based on the same conditions, but also includes the marginal glosses of ÖNB 1239. Here we reached a CER of 13.6%, which is actually quite good considering the very small glosses and our experimental method. Due to this approach, our team was also able to publish three different transcription sets on Zenodo (transcriptions of ÖNB 473, ÖNB 1239 without glosses and ÖNB 1239 containing marginal glosses). Thus, we are very satisfied with the results, on the one hand, having produced a useful model with a CER of 5.1% and, on the other hand, having undertaken pioneering work on glossed manuscripts in Transkribus.
Dataset created by Carolingian Latin group is available online on Zenodo: https://doi.org/10.5281/zenodo.10610704.
Late Medieval Latin Group
The group was led by Jan Odstrčilík, Martin Roček and Ivana Lukáč Labancová. We followed-up on our work from last year by producing more ground truth for the manuscript ÖNB 3891. We focused on the part containing Sermons by the theologian and university master in Vienna Thomas Ebendorfer (+1464). These sermons are yet to be published and focus mainly on the topics of confession, penitence and various sins. This part was written by the scribe Wolfgang Chranekker in bastarda in 1441 in St. Wolfgang. His writing is, unfortunately, quite challenging for readers due to the number of scribal errors and complicated abbreviations, which also makes the preparation of the ground truth more time consuming.
Last year, we experimented with two different approaches: diplomatic transcription without expansion of abbreviations and semi-diplomatic transcription with expansion of abbreviations. Because the former proved to be very time consuming without providing substantially better results, this year we decided to focus solely on the semi-diplomatic transcription.
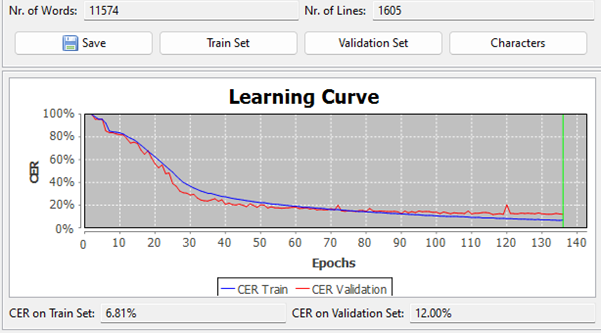
Our best model last year (trained without using any other model as a base): see Figure 3.
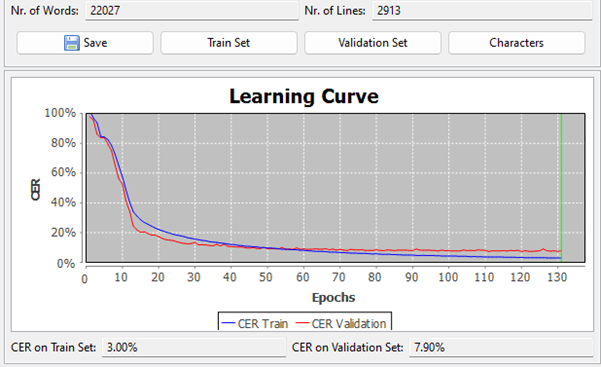
Our best model this year (trained without using any other model as a base): see Figure 4.
The improvement is thus very large, and the resulting text is rather legible, although still not perfect (fol. 3v with an automatic transcription from the validation set): see Figure 5.
One of the most important choices we had to make was which selection of pages in the manuscript we would transcribe. Originally, we transcribed continuously from the beginning. However, we noticed that this caused the model to behave peculiarly: even though the handwriting itself was identical throughout the entire collection, the quality of the reading deteriorated continuously. Transcribing two additional pages from the end of the sermon collection resulted in an improvement in consistency. We suspect that this is related to the changing vocabulary throughout the collection, due to the wide-ranging topics, which meant new Latin abbreviations that the model was not familiar with. Transkribus uses recurrent neural networks to predict sequences of letters, and thus unknown words may be more difficult for Transkribus: we therefore recommend that you take samples from different parts of the text and not just from one part.
Dataset created by Late Latin group is available online on Zenodo: https://doi.org/10.5281/zenodo.10589479.
Byzantine Group
This year, the HTR Winter School in Vienna included a group for Byzantine Greek, led by Eirini Afentoulidou (Austrian Academy of Sciences) and Ekaterini Mitsiou (University of Vienna). We worked with two manuscripts: Dresden, SLUB A. 151 (15th century) and Paris. gr. 1382 (14th century). The former is a liturgical manuscript with a highly legible script, and is accessible via a high-quality digitization. The latter is a legal manuscript which is also available online for free, though the quality of the pictures in this digitization is poorer. Consequently, the digitizations also presented some difficulties for our group, which the participants had to identify and correct.
In the course of the project, we focused on Dresden A. 151, and we created the model “15th c. liturgical”. The training set size was substantial, coming in at 6,784 words, and the resulting error rate was 22.30%, which is quite high.
The high error rate can be attributed to two main factors: a) our decision to include accents for philological reasons, and b) our reliance solely on automatic layout recognition due to time and resource constraints. Consequently, the AI generated line regions mostly left out many of the accents which a human transcriber would not have. Similarly, medieval scribes of Greek manuscripts often placed suffixes, whether abbreviated or not, above the line, resulting in similar issues for our layout recognition. Indeed, these two issues were responsible for a majority of the errors in the automatic transcription: whenever Transkribus correctly placed accents or provided suffixes positioned outside the line region, it was due to our training, which caused it to recognize these new diacritical patterns.
Similarly, we made the editorial decision to consistently include iota subscriptum in the transcriptions, even though the scribes of the manuscripts we utilized never did so: Transkribus accurately placed the iota subscriptum at a relatively high rate. We suspect that this was because the usage of iota subscriptum is largely confined to specific suffixes within nominal and verbal paradigms, making it easier for our model to identify patterns.
Due to the high error rate, our current model is of limited utility for establishing a basis for an edition. However, it proves valuable for generating searchable transcriptions, especially when utilizing the "fuzzy search" option available in the "Expert Client" version.
Dataset created by Byzantine Group is available online on Zenodo: https://doi.org/10.5281/zenodo.10590389.
Czech Group
The Czech group was supported by the Austrian Academy of Sciences within the cooperation project “König Ottokar’s Glück und Ende: Das lange 13. Jahrhundert in den ostmitteleuropäischen Ländern - Politik, Kultur und Identität”.
The Czech team at the winter school worked on the manuscript of the New Testament by Martin Lupáč (ÖNB Cod. 3304). This effort built upon the work from the previous year's winter school, which saw the public release of the models “Old Czech Handwriting (with spaces)”. From this year we also expect the publication of a new public model, which will be more broadly applicable to Czech medieval manuscripts written in bastarda script.
The Czech team enjoyed a friendly atmosphere with the promise of collaboration on future projects related to training models for HTR for the Czech language. Given the limited availability of datasets for Slavic languages, this school hopefully provided students with intriguing prospects in this segment of the workshop. As a follow-up to the Winter School, a forum on Discord was also created to bring together researchers working with Transkribus and HTR in the context of Slavic languages.
Dataset created by Czech Group is available online on Zenodo: https://doi.org/10.5281/zenodo.10619017.
Future
We are already planning HTR Winter School 2024. Based on the collected feedback, we will devote more time to transcribing manuscripts (probably 3 virtual sessions) and more time in-person in Vienna (3 days). We intend to also expand the languages we have on offer, ideally including German and possibly Hebrew and Syriac. We will announce the new Winter School for HTR of medieval manuscripts in June 2024.